
La giustizia predittiva, quali sono gli aspetti controversi e i suoi sviluppi più prossimi
Di Luca Menichno.
Intelligenza artificiale e giustizia predittiva, parole affascinati che evocano il futuro. Si parla di macchine dotate di intelligenza artificiale che, dopo aver appreso dai precedenti, sono in grado di predire automaticamente quale sarà l’esito della lite.
Si tratta di una soluzione tecnica che risponde alla inevitabile soggettività delle decisioni giudiziarie. Per i fautori di questi sistemi l’intelligenza artificiale sarebbe cioè lo strumento per assicurare una giustizia più certa, più omogenea, in grado di ridurre fino a eliminare la discrezionalità e i pregiudizi di ogni decisione. Questi strumenti poi potrebbero affinarsi a tal punto da sostituire il Giudice nell’elaborazione della sentenza. Ma come funzionano questi software predittivi più avanzati che si fondano sull’intelligenza artificiale e sull’apprendimento automatico?
L’uomo inserisce nella macchina i dati di fatto che hanno portato alla lite; la macchina, raffrontando i fatti inseriti con quelli che risultano dalle descrizioni che sono fatte nelle motivazioni dei precedenti che costituiscono il suo database, crea una correlazione tra i due elementi (si convertono in dati numerici le strutture lessicali e le si pone in relazione con le strutture lessicali contenute nella decisione) e individua, tra quei precedenti, le decisioni che appaiono più affini e, dunque, più probabili. Si creano così delle correlazioni tra gli input (i fatti della lite-la motivazione) e l’output (la decisione). Più in particolare, la macchina individua un insieme di parole tratte da un testo (ossia i fatti della lite e la decisione finale) che vengono connesse in via probabilistica tra loro attribuendo a ciascuna un valore matematico che avvicini quelle che sembrano avere maggiore connessione sul piano semantico, allontanando quelle che sembrano avere un significato meno prossimo. In questo modo i fatti della lite vengono associati alle decisioni più adeguate, attraverso un processo che, allo stato, sarebbe puramente meccanicistico.
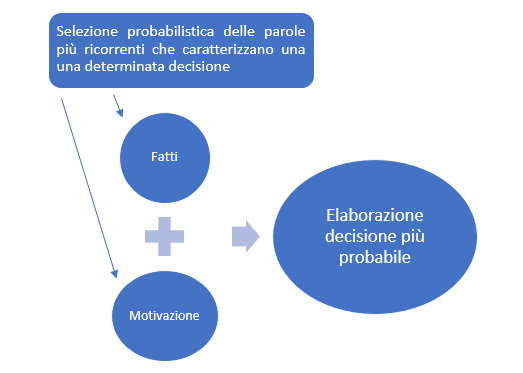
Così, per semplificare al massimo livello: se nei fatti della lite vi sono riferimenti a un tradimento, un adulterio, alla infedeltà coniugale, la macchina riconosce la correlazione probabilistica tra le prime voci e la separazione con addebito pronunciata nella maggioranza dei casi in cui rinviene quegli elementi di fatto, eliminando le correlazioni meno probabili. E così in presenza di un certo contesto semantico, la macchina automaticamente assocerà ai fatti (tradimento) la correlazione più probabile (la separazione con addebito).
Ovviamente l’ipotesi che una macchina possa anche solo suggerire l’azione dei giudici è colma di implicazioni etiche. Sono già emerse diverse perplessità, che ha ben messo in evidenza anche la Commissione Europea per l’Efficienza della Giustizia (CEPEJ) nel 2018 con la “Carta Etica sull’utilizzo dell’intelligenza artificiale nei sistemi giudiziari e negli ambiti connessi”.
In massima sintesi questi sono gli elementi più controversi.
1. Chi progetta il software fornisce le istruzioni alla macchina e le istruzioni possono essere conseguenza di un pregiudizio, anche inconscio; anche il risultato soffrirà poi degli stessi pregiudizi.
2. L’individuazione delle decisioni avviene sulla base dei precedenti acquisiti dal computer; adeguarsi alla decisione offerta dalla macchina di fatto farebbe venir meno la possibilità di decisioni nuove che si adeguino rispetto alle mutate esigenze o rispetto ad altre e nuove prospettive, che non erano state sottoposte prima all’attenzione dei giudici. Il meccanismo decisionale sarebbe meramente riproduttivo, con un appiattimento e una omogeneizzazione eccessiva, che non tiene conto della varietà delle diverse situazioni (e del mutare della società e dei suoi valori).
3. La macchina individua le soluzioni, ma quando esiste una gran mole di dati, vi è un rischio molto alto di false correlazioni, che si traducono poi in decisioni sbagliate. Del resto, ricordiamoci che la correlazione semantica è fondata su un modello probabilistico, per cui più sono i dati acquisiti, più sono possibili false correlazioni; ciò è pure aggravato dal fatto che la macchina già seleziona la decisione sulla base di un calcolo di probabilità rispetto ai precedenti, il che può quindi introdurre un ulteriore fattore di incertezza.
4. I modelli matematici sono destinati a fallire se le sentenze presentano aspetti di scarsa chiarezza, o errori, o contraddizioni o ancora valutazioni implicite, comprensibili al lettore (tecnico della materia), ma non alla macchina. Lo stesso discorso vale quando la motivazione è molto succinta, per cui la macchina avrebbe difficoltà a trovare le correlazioni linguistiche sufficienti per giungere a una conclusione coerente; a ciò si aggiunga che ciascun giudice scrive in modo diverso, organizza il pensiero in modo diverso, per cui tutte queste variabili soggettive rendono più difficile il riconoscimento linguistico dei fatti e delle correlazioni operato dalla macchina.
5. Le decisioni non sono tutte coerenti e, anzi, non sono insoliti i contrasti (più o meno chiari) tra le varie decisioni; anche questo è un fattore che genera confusione, per cui non esistendo una chiara correlazione tra fatti e decisione, il rischio di decisioni automatiche illogiche è piuttosto alto.
6. Una decisione di primo grado non impugnata non necessariamente è corretta sul piano del diritto, né è necessariamente ben motivata. Se la macchina trova delle correlazioni tra fatti e decisioni alla stregua di precedenti di bassa qualità può commettere gravi errori, perché non è in grado di comprendere se la decisione sia legittima o meno.
7. Nella valutazione giudiziaria il Giudice individua i fatti rilevanti che risultano accertati e fa una scelta: la macchina non è in grado di individuare da sola i fatti rilevanti di un caso, il peso da attribuire a ciascun fatto, né di capire quali sono i fatti accertati o accertabili per poi giungere a una decisione; la macchina deve fidarsi di quanto rinviene nei precedenti, correlando le parole che riconosce, ma senza saper dare un peso all’importanza di quelle parole ai fini della decisione.
In definitiva, anche il CEPEJ ha evidenziato che i procedimenti meccanicistici mal si adattano alle scienze sociali come il diritto.
Almeno ad oggi, se l’intendimento è sostituire l’uomo, l’ipotesi di una decisione affidata all’algoritmo è ancora di là da venire; una idea fittizia, che vede nella macchina più di quel che ora la macchina può offrire (anche lasciando da parte i quesiti strettamente etici che pone una giustizia “robotizzata”). Tuttavia, l’associazione di dati legati all’uso dell’intelligenza artificiale già a breve termine può comunque dare un grande contributo.
Con l’intelligenza artificiale sarà possibile classificare, classificare automaticamente; se questa opzione è associata alle pubblicazioni di tutte le decisioni di merito di ciascun Tribunale, Corte d’Appello e a quelle della Corte di Cassazione, all’evidenza si potrebbe formare un gigantesco database che, con ragionevole probabilità, potrebbe ordinare le decisioni, mettendo in evidenza le tendenze maggioritarie rispetto a quelle minoritarie e a quelle isolate, distinguendo le decisioni sia in base alle circostanze di fatto che le hanno originate, sia escludendo dai precedenti o separando le decisioni di merito che risultano poi riformate dalle Corti Superiori.
Questa frontiera – che almeno allo stato appare quella più ragionevolmente prossima – avrebbe degli straordinari benefici: per i giudici, i quali avrebbero maggiore facilità a ricercare filoni giurisprudenziali che li avvicinino alla fattispecie da loro esaminate in vista di una maggiore semplificazione della loro attività; per gli avvocati, per fornire una risposta ancora più puntuale ai loro clienti e avere più strumenti per predire l’esito di una lite, evitando inutili e costose controversie giudiziarie; ma anche per il sistema giudiziario e per la società: in primo luogo, perché una maggiore conoscenza dei rischi dovrebbe determinare una riduzione del contenzioso e dei costi (anche collettivi) connessi; in secondo luogo perché un data base open source legato agli orientamenti delle corti – anche territoriali – consentirebbe un monitoraggio statistico costante delle decisioni all’interno della magistratura, che consentirebbe di adottare dei correttivi nella logica di una maggiore coerenza interna. Infine, perché un insieme facilmente consultabile di decisioni giudiziarie costituisce uno strumento più efficace per dare pubblicità e per raggiungere una maggiore trasparenza democratica.
Ecco che, se declinata quale strumento di supporto e ausilio, la tecnologia sarebbe davvero uno strumento al servizio del cittadino.
Milano, 09 marzo 2022